تفاوت بین هوش مصنوعی، یادگیری ماشین و یادگیری عمیق چیست؟
تفاوت بین هوش مصنوعی
سفری از مفاهیم پایه تا پیشرفته هوش مصنوعی
هوش مصنوعی، یادگیری ماشین و یادگیری عمیق – بخش دوم از آموزش های هوش مصنوعی
تفاوت بین هوش مصنوعی، یادگیری ماشین و یادگیری عمیق چیست؟ در بخش اول آموزش هوش مصنوعی به بیان تاریخچه ای از هوش مصنوعی پرداخیتم. در این بخش ، ما به دنیای شگفتانگیز هوش مصنوعی (AI)، یادگیری ماشین (ML) و یادگیری عمیق (DL) قدم میگذاریم. این سه مفهوم که اغلب به جای یکدیگر به کار میروند، در واقع لایههایی از یک ایده بزرگتر هستند که نحوه تعامل ماشینها با دنیای اطرافشان را تعریف میکنند. درک تفاوتها و ارتباط بین آنها برای هر کسی که میخواهد درک عمیقتری از فناوریهای امروزی پیدا کند، ضروری است. سرویس آموزش فناوری از خبر ICT در این بخش به بیان این تفاوت ها و تعاریف خواهد پرداخت.
۱.۱ هوش مصنوعی (Artificial Intelligence – AI): رویای دیرینه انسان
۱.۱.۱ تعریف و فلسفه:
هوش مصنوعی (AI) به طور کلی به شاخهای از علوم کامپیوتر گفته میشود که هدف آن خلق سیستمها یا ماشینهایی است که بتوانند وظایفی را انجام دهند که به طور معمول نیازمند هوش انسانی هستند. این وظایف شامل موارد زیر است:
- استدلال و حل مسئله (Reasoning & Problem Solving): توانایی تحلیل اطلاعات، نتیجهگیری منطقی و یافتن راهحل برای مشکلات.
- یادگیری (Learning): توانایی کسب دانش و مهارت از تجربه یا دادهها.
- ادراک (Perception): توانایی درک محیط اطراف از طریق حواس (مانند دیدن، شنیدن، لمس کردن).
- پردازش زبان طبیعی (Natural Language Processing – NLP): توانایی درک، تفسیر و تولید زبان انسانی.
- برنامهریزی (Planning): توانایی تعیین اهداف و یافتن مسیرهای عملی برای رسیدن به آنها.
- حرکت و دستکاری (Motion & Manipulation): توانایی کنترل حرکات فیزیکی در دنیای واقعی.
فلسفه پشت AI، بازآفرینی یا شبیهسازی جنبههایی از هوش انسانی در ماشینها است تا بتوانند به طور مستقل یا نیمهمستقل عمل کرده و تصمیمگیری کنند.
۱.۱.۲ تاریخچه مختصر:
ایده ساخت موجودات مصنوعی هوشمند به دوران باستان بازمیگردد (اسطورهها و داستانها)، اما حوزه علمی AI در سال ۱۹۵۶ در «کارگاه دالتون» رسماً پایهگذاری شد. از آن زمان تاکنون، AI دورههای پر فراز و نشیبی را طی کرده است:
- دورههای امیدواری اولیه (دهههای ۵۰ و ۶۰): پیشرفتهای اولیه در حل مسائل منطقی و بازیها.
- «زمستانهای AI» (دهههای ۷۰ و ۸۰): ناامیدی ناشی از نرسیدن به وعدههای بزرگ و کاهش بودجه تحقیقاتی.
- ظهور سیستمهای خبره (Expert Systems – دهههای ۸۰ و ۹۰): سیستمهایی که دانش تخصصی یک حوزه را شبیهسازی میکردند.
- انقلاب دادهها و قدرت محاسباتی (قرن ۲۱): با افزایش حجم دادهها (Big Data) و قدرت پردازشی کامپیوترها، AI دوباره جان گرفت و شاهد پیشرفتهای چشمگیری بودیم.
۱.۱.۳ انواع AI:
AI را میتوان به دو دسته اصلی تقسیم کرد:
- AI ضعیف یا محدود (Narrow or Weak AI): این نوع AI برای انجام یک وظیفه خاص طراحی شده است. تقریباً تمام AIهای امروزی در این دسته قرار میگیرند. مثالها: Siri، دستیارهای صوتی، سیستمهای توصیهگر، نرمافزارهای تشخیص چهره.
- AI قوی یا عمومی (General or Strong AI – AGI): این نوع AI دارای هوشی در سطح انسانی است و میتواند هر وظیفه فکری را که یک انسان قادر به انجام آن است، یاد بگیرد و انجام دهد. AGI هنوز یک هدف تحقیقاتی بلندمدت است و وجود خارجی ندارد.
- فرا-هوش مصنوعی (Superintelligence – ASI): هوشی که از هوش بهترین مغزهای انسانی در تقریباً هر زمینهای، از جمله خلاقیت علمی، خرد عمومی و مهارتهای اجتماعی، بسیار برتر است. این مفهوم بیشتر در قلمرو تئوری و فلسفه قرار دارد.
۱.۱.۴ کاربردها:
AI در حال حاضر در صنایع مختلفی کاربرد دارد: پزشکی (تشخیص بیماری)، مالی (تشخیص تقلب)، حمل و نقل (خودروهای خودران)، سرگرمی (بازیها، توصیهگرها)، خدمات مشتری (چتباتها) و بسیاری موارد دیگر.
۱.۲ یادگیری ماشین (Machine Learning – ML): هوش مصنوعی که از تجربه میآموزد
۱.۲.۱ جایگاه ML در AI:
یادگیری ماشین (ML) یکی از زیرشاخههای اصلی و پرکاربردترین رویکردها در AI است. هدف ML این است که به سیستمهای کامپیوتری این توانایی را بدهد که بدون برنامهریزی صریح، از دادهها یاد بگیرند و عملکرد خود را بهبود بخشند. به عبارت دیگر، به جای اینکه به کامپیوتر بگوییم «چگونه» یک کار را انجام دهد، به او داده میدهیم و میگذاریم خودش «یاد بگیرد» که چگونه انجام دهد.
۱.۲.۲ نحوه عملکرد (الگوریتمها و دادهها):
الگوریتمهای ML بر اساس دریافت دادههای ورودی، یافتن الگوها و ساخت مدلهایی که میتوانند پیشبینی یا تصمیمگیری کنند، کار میکنند. این فرآیند معمولاً شامل مراحل زیر است:
- جمعآوری داده: دادههای مرتبط با مسئله جمعآوری میشوند.
- پیشپردازش داده (Data Preprocessing): دادهها تمیز، نرمالسازی و آمادهسازی میشوند (حذف دادههای پرت، پر کردن مقادیر گمشده و…).
- انتخاب ویژگی (Feature Selection/Engineering): مهمترین ویژگیها یا پارامترهای دادهها شناسایی یا ساخته میشوند.
- انتخاب مدل: الگوریتم ML مناسب برای مسئله انتخاب میشود.
- آموزش مدل (Model Training): مدل با استفاده از دادههای آموزشی، الگوها را یاد میگیرد.
- ارزیابی مدل (Model Evaluation): عملکرد مدل با استفاده از دادههای تست (که در آموزش استفاده نشدهاند) سنجیده میشود.
- تنظیم هایپرپارامترها (Hyperparameter Tuning): پارامترهای مدل برای بهینهسازی عملکرد تنظیم میشوند.
- استقرار (Deployment): مدل نهایی برای استفاده در دنیای واقعی آماده میشود.
۱.۲.۳ انواع اصلی ML:
ML را میتوان به سه دسته اصلی تقسیم کرد:
-
یادگیری با نظارت (Supervised Learning):
-
توضیح: در این روش، دادههای آموزشی شامل جفتهای ورودی-خروجی هستند (یعنی برای هر ورودی، خروجی صحیح مشخص است). هدف مدل، یادگیری تابعی است که ورودی را به خروجی نگاشت کند.
-
مثال: آموزش مدلی برای تشخیص تصاویر گربه و سگ، با دادن هزاران تصویر که برچسب «گربه» یا «سگ» دارند.
-
دو نوع اصلی:
-
طبقهبندی (Classification): پیشبینی یک دسته یا برچسب گسسته (مثال: اسپم/غیراسپم، بیمار/سالم).
-
رگرسیون (Regression): پیشبینی یک مقدار پیوسته (مثال: پیشبینی قیمت خانه، دمای هوا).
-
-
یادگیری بدون نظارت (Unsupervised Learning):
-
توضیح: در این روش، دادههای آموزشی فاقد برچسب خروجی هستند. هدف مدل، یافتن ساختارها، الگوها یا روابط پنهان در دادههاست.
-
مثال:
-
خوشهبندی (Clustering): گروهبندی دادههای مشابه با هم (مثال: تقسیم مشتریان به گروههای مختلف بر اساس رفتار خریدشان).
-
کاهش ابعاد (Dimensionality Reduction): سادهسازی دادهها با کاهش تعداد ویژگیها، ضمن حفظ اطلاعات مهم.
-
قوانین وابستگی (Association Rule Mining): یافتن روابط بین اقلام (مثال: مشتریانی که نان میخرند، احتمالاً شیر هم میخرند).
-
-
یادگیری تقویتی (Reinforcement Learning – RL):
-
توضیح: در این روش، یک عامل (Agent) در یک محیط (Environment) یاد میگیرد که چگونه با انجام اقدامات (Actions)، پاداش (Reward) حداکثری را کسب کند. عامل از طریق آزمون و خطا یاد میگیرد.
-
مثال: آموزش یک ربات برای راه رفتن (پاداش برای هر قدم موفق، جریمه برای افتادن)، آموزش سیستم برای بازی کردن (پاداش برای برنده شدن). بازی AlphaGo گوگل نمونهای مشهور از RL است.
-
۱.۲.۴ کاربردها:
ML در پیشنهاد محصولات (آمازون، دیجیکالا)، تشخیص پزشکی، پیشبینی بازار سهام، سیستمهای توصیهگر (موسیقی، فیلم)، رباتیک، و بسیاری از سیستمهای هوشمند دیگر کاربرد دارد.
۱.۳ یادگیری عمیق (Deep Learning – DL): قدرتمندترین زیرشاخه ML
۱.۳.۱ ریشهها در شبکههای عصبی:
یادگیری عمیق (DL) زیرشاخهای از یادگیری ماشین است که از شبکههای عصبی مصنوعی (Artificial Neural Networks – ANN) با لایههای متعدد (عمیق) الهام گرفته از ساختار مغز انسان استفاده میکند. این شبکهها قادر به یادگیری نمایشهای سلسله مراتبی از دادهها هستند.
۱.۳.۲ معماری شبکههای عصبی عمیق:
یک شبکه عصبی پایه از نورونهای (Neurons) مصنوعی تشکیل شده است که در لایهها (Layers) سازماندهی شدهاند:
- لایه ورودی (Input Layer): دادههای خام را دریافت میکند.
- لایههای پنهان (Hidden Layers): بین لایه ورودی و خروجی قرار دارند. هر لایه، نمایش پیچیدهتری از دادهها را نسبت به لایه قبلی یاد میگیرد. در DL، تعداد این لایهها زیاد است (از چند لایه تا صدها لایه).
- لایه خروجی (Output Layer): نتیجه نهایی (پیشبینی، طبقهبندی و…) را تولید میکند.
هر نورون در یک لایه، سیگنالهایی را از نورونهای لایه قبلی دریافت میکند، آنها را با وزنهای خاصی ترکیب کرده، یک تابع فعالسازی (Activation Function) روی آن اعمال میکند و نتیجه را به لایه بعدی میفرستد.
۱.۳.۳ چرا «عمیق»؟
«عمیق» بودن به معنای داشتن لایههای پنهان متعدد است. این لایههای اضافی به شبکه اجازه میدهند تا ویژگیهای انتزاعیتر و پیچیدهتری را به صورت خودکار از دادهها استخراج کند.
- مثال (تشخیص تصویر):
- لایههای اول ممکن است لبهها، گوشهها و خطوط ساده را تشخیص دهند.
- لایههای میانی ترکیب این ویژگیها را یاد میگیرند (مانند بافتها، اشکال ساده).
- لایههای عمیقتر، اجزای پیچیدهتر (مانند چشم، چرخ، پلاک) و در نهایت اشیاء کامل (چهره، ماشین، گربه) را تشخیص میدهند.
۱.۳.۴ انواع معماریهای DL:
معماریهای DL مختلفی برای وظایف گوناگون وجود دارند:
- شبکههای عصبی کانولوشنی (Convolutional Neural Networks – CNNs): ایدهآل برای پردازش دادههای شبکهای مانند تصاویر. در تشخیص تصویر و ویدئو بسیار موفق بودهاند.
- شبکههای عصبی بازگشتی (Recurrent Neural Networks – RNNs): مناسب برای دادههای ترتیبی مانند متن و سریهای زمانی. قادر به حفظ «حافظه» از ورودیهای قبلی هستند. مدلهای پیشرفتهتر مانند LSTM و GRU بهبودهایی در این زمینه هستند.
- ترنسفورمرها (Transformers): معماری نسبتاً جدیدتر که در پردازش زبان طبیعی (NLP) انقلابی ایجاد کرده و اساس مدلهای زبانی بزرگ (LLMs) مانند GPT است.
۱.۳.۵ مزایا و معایب DL:
- مزایا:
- عملکرد فوقالعاده در وظایف پیچیده (تشخیص تصویر، صدا، زبان).
- استخراج خودکار ویژگیها (کاهش نیاز به مهندسی ویژگی دستی).
- توانایی یادگیری از حجم عظیم داده.
- معایب:
- نیاز به حجم بسیار زیادی داده برای آموزش.
- نیاز به قدرت محاسباتی بالا (GPU/TPU).
- اغلب به عنوان «جعبه سیاه» (Black Box) در نظر گرفته میشود؛ درک چرایی تصمیمگیری مدل دشوار است (تفسیرپذیری کم).
- زمانبر بودن فرآیند آموزش.
۱.۳.۶ کاربردها:
DL در پیشرفتهای اخیر در بینایی ماشین (Computer Vision)، پردازش زبان طبیعی (NLP)، تشخیص گفتار، سیستمهای خودران، کشف دارو، و بسیاری حوزههای علمی و صنعتی نقش کلیدی داشته است.
۱.۴ جمعبندی و ارتباط بین مفاهیم در موضوع تفاوت بین هوش مصنوعی
- AI یک هدف کلی است: ساخت ماشینهای هوشمند.
- ML یک رویکرد برای دستیابی به AI است: یادگیری از دادهها.
- DL یک تکنیک پیشرفته در ML است: استفاده از شبکههای عصبی عمیق برای یادگیری الگوهای پیچیده.
میتوانیم این را به صورت نمودار ون (Venn Diagram) تصور کنیم که دایره ML درون دایره AI و دایره DL درون دایره ML قرار دارد. هرچند، باید توجه داشت که همیشه مرزهای کاملاً مشخصی وجود ندارد و برخی تکنیکها ممکن است بین این دستهبندیها قرار گیرند.
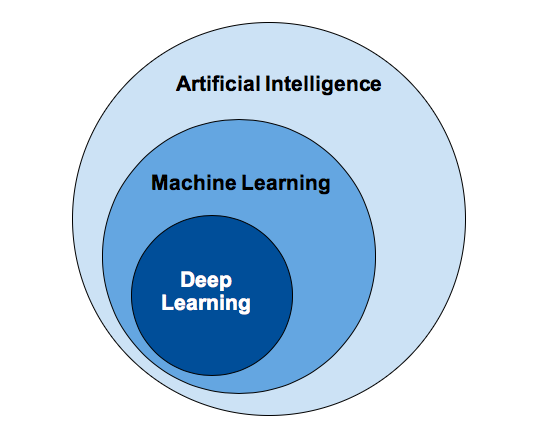
درک این تمایزها به ما کمک میکند تا بفهمیم هر تکنولوژی چگونه کار میکند، چه محدودیتهایی دارد و برای چه نوع مسائلی مناسبتر است. این دانش پایه، ما را برای درک عمیقتر مباحث پیشرفتهتر در هوش مصنوعی آماده میسازد.
تحقیق و تدوین مهدی گمرکی




